Compare Scores Visually
Procedure
This procedure assesses whether the performance of machine learning models on the train and test sets exhibits similar distributions. This test helps determine if the model generalizes effectively to unseen data, ensuring that train/test splits are meaningful.
-
Evaluate Performance on Train Set
- What to do: Test each algorithm in the chosen suite on the train set.
- Use a consistent test harness, such as 10-fold cross-validation.
- Record the performance metrics (e.g., accuracy, RMSE) for each algorithm.
- What to do: Test each algorithm in the chosen suite on the train set.
-
Evaluate Performance on Test Set
- What to do: Apply the same algorithms to the test set.
- Evaluate using the same performance metrics as in the train set evaluation.
- Confirm that no data leakage has occurred between train and test sets.
- What to do: Apply the same algorithms to the test set.
-
Gather Performance Metrics
- What to do: Collect performance scores for each algorithm from both the train and test evaluations.
- Organize the results in a structured format, such as a table with rows for algorithms and columns for train and test performance metrics.
- What to do: Collect performance scores for each algorithm from both the train and test evaluations.
-
Visualize Performance Comparison
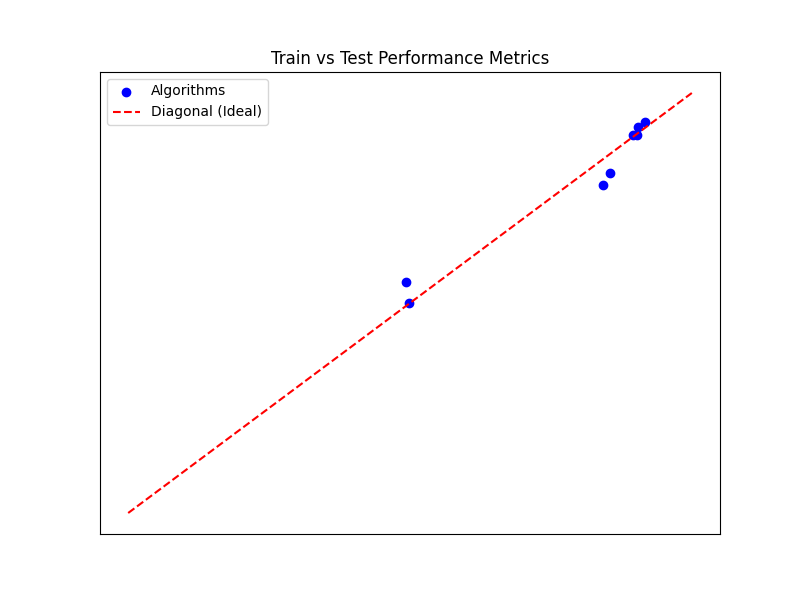
- What to do: Create a scatter plot of train scores versus test scores for all algorithms.
- Include a diagonal line representing the expected equality of train and test performance.
- Highlight points that deviate significantly from the diagonal.
- What to do: Create a scatter plot of train scores versus test scores for all algorithms.
-
Check Distribution Assumptions
- What to do: Analyze the scatter plot and distributions of train and test scores.
- Assess whether the points align closely with the diagonal, indicating similar distributions.
- Look for patterns of overfitting (train scores significantly better than test) or underfitting (both scores poor).
- What to do: Analyze the scatter plot and distributions of train and test scores.
-
Interpret the Results
- What to do: Evaluate whether the observed train and test performance distributions align with expectations.
- Consistent performance suggests the train/test split is effective, and the model generalizes well.
- Significant deviations may indicate issues such as overfitting, poor data preprocessing, or an unrepresentative train/test split.
- What to do: Evaluate whether the observed train and test performance distributions align with expectations.
-
Report Findings
- What to do: Summarize the observations and implications of the test.
- Present the scatter plot and provide insights into the alignment (or misalignment) of train and test scores.
- Note: Omit labels on the axis to avoid data leakage.
- Use error bars for each point to represent the distribution for each algorithm score on train/test sets.
- Highlight any concerning trends, such as algorithms consistently underperforming on the test set, and recommend next steps (e.g., revisit data preprocessing, adjust the split ratio, or try different algorithms).
- What to do: Summarize the observations and implications of the test.
Code Example
This Python function evaluates the consistency of train and test set performance for a suite of machine learning algorithms by visualizing their performance metrics on a scatter plot.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import cross_val_score
from sklearn.metrics import make_scorer
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.dummy import DummyClassifier
def evaluate_train_test_split(X_train, y_train, X_test, y_test, metric, k):
"""
Evaluate the quality of the train/test split by comparing model performance metrics visually.
Parameters:
X_train, y_train: training features and target labels.
X_test, y_test: testing features and target labels.
metric (callable): A performance metric function, e.g., accuracy_score.
k (int): Number of folds for k-fold cross-validation.
Returns:
None: Displays a scatter plot of train vs test scores.
"""
# Define a suite of machine learning algorithms
algorithms = [
LogisticRegression(max_iter=1000),
DecisionTreeClassifier(),
KNeighborsClassifier(),
SVC(probability=True),
RandomForestClassifier(n_estimators=50),
GradientBoostingClassifier(),
DummyClassifier(strategy="most_frequent"),
DummyClassifier(strategy="stratified"),
]
train_scores = []
test_scores = []
# Evaluate performance for each algorithm
for model in algorithms:
# Cross-validation on train set
train_cv_scores = cross_val_score(model, X_train, y_train, scoring=make_scorer(metric), cv=k)
train_scores.append(np.mean(train_cv_scores))
# Cross-validation on test set
test_cv_scores = cross_val_score(model, X_test, y_test, scoring=make_scorer(metric), cv=k)
test_scores.append(np.mean(test_cv_scores))
# Scatter plot of train vs test scores
plt.figure(figsize=(8, 6))
plt.scatter(train_scores, test_scores, color="blue", label="Algorithms")
plt.plot([0, 1], [0, 1], linestyle="--", color="red", label="Diagonal (Ideal)")
plt.gca().set_xticks([]) # Remove axis label values to avoid data leakage
plt.gca().set_yticks([]) # Remove axis label values to avoid data leakage
plt.title("Train vs Test Performance Metrics")
plt.legend()
plt.show()
# Demo Usage
if __name__ == "__main__":
from sklearn.datasets import make_classification
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
# Generate synthetic dataset
X, y = make_classification(
n_samples=500, n_features=10, n_informative=5, random_state=42
)
# Split into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Perform the diagnostic test
evaluate_train_test_split(
X_train, y_train,
X_test, y_test,
metric=accuracy_score,
k=10
)Example Output